publications
List of publications, including published and submitted papers.
2026
- Under Review
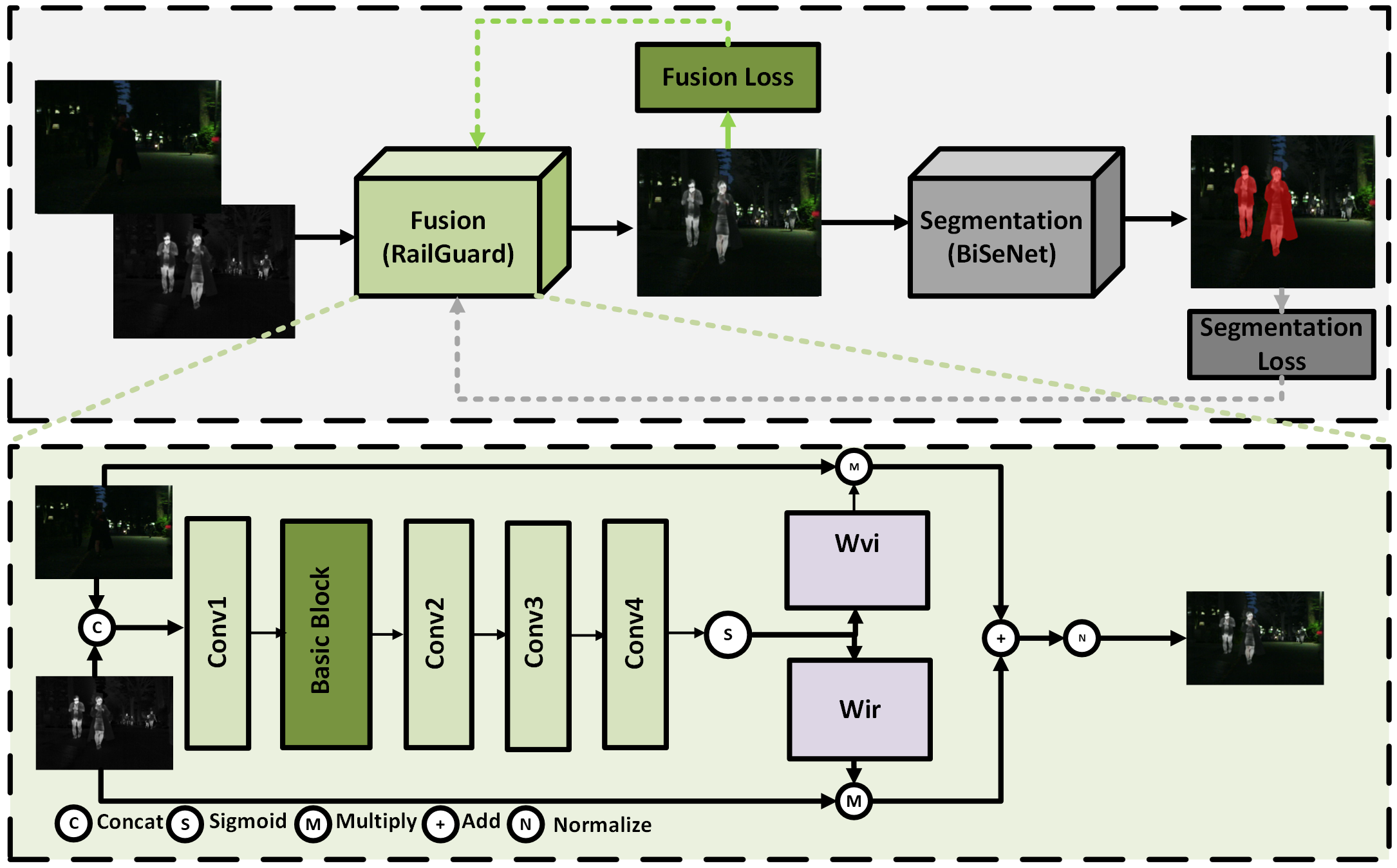 RailGuard: A Detection-Guided Infrared and Visible Image Fusion Framework for Enhanced Rail SafetyMuhammad Faizan, Muhammad Hammad, Abid Rafique, and 1 more authorIEEE Transactions on Vehicular Technology, 2026Under Review
RailGuard: A Detection-Guided Infrared and Visible Image Fusion Framework for Enhanced Rail SafetyMuhammad Faizan, Muhammad Hammad, Abid Rafique, and 1 more authorIEEE Transactions on Vehicular Technology, 2026Under ReviewRailway transportation is a reliable and economical mode of transport in many countries worldwide. Despite its affordability and widespread use, it suffers from a poor safety record specifically in developing countries, with numerous accidents occurring, particularly at unmanned level crossings due to road user negligence. One promising approach to enhancing railway safety involves leveraging advanced imaging techniques to improve hazard detection and monitoring. Image fusion integrates complementary information from multiple modalities such as infrared and visible images. However, previous approaches have overlooked the potential of image fusion in railway applications. Moreover, most state-of-the-art methods perform poorly in real-time edge applications, such as deployment on Jetson devices, limiting their use in locomotive systems. Furthermore, there is no standard benchmark for evaluating fusion algorithms in the context of railway data. This paper introduces RailGuard, a joint image fusion and semantic segmentation framework optimized for edge devices. The proposed system cascades image fusion and semantic segmentation network, enabling both tasks to learn representations jointly. The model is optimized for edge devices to ensure minimal runtime. It achieves an inference time of 6.3 ms on a Tesla T4 and 4.92 ms on Jetson Orin Nano for the fusion of a 320×320 image pair. A comprehensive benchmark was established to support the evaluation of fusion techniques in railway applications, covering diverse rail scenarios. Extensive experiments on TNO, Road Scene, MSRS, and the proposed RRL datasets demonstrate that the proposed method delivers effective fusion and achieves real-time performance on Jetson Orin Nano.
@article{faizan2025railguard, title = {{RailGuard: A Detection-Guided Infrared and Visible Image Fusion Framework for Enhanced Rail Safety}}, author = {Faizan, Muhammad and Hammad, Muhammad and Rafique, Abid and Cheema, Hammad M.}, journal = {IEEE Transactions on Vehicular Technology}, year = {2026}, note = {Under Review}, } - Under Review
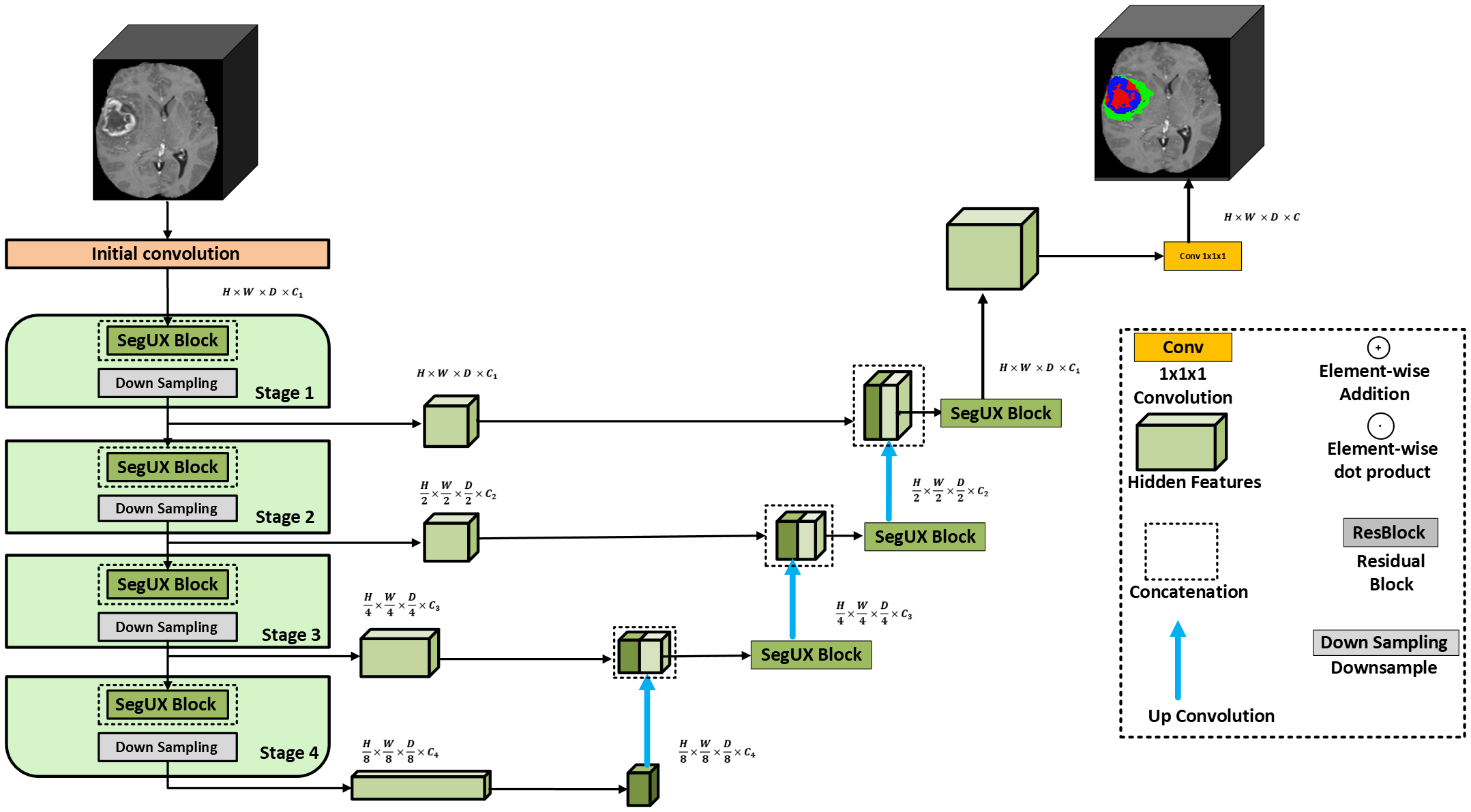 3D SegUX-Net: Multi-Modal MRI Segmentation Using Large KernelsMuhammad Faizan, Sara Ali, Usman Zia, and 1 more authorComputerized Medical Imaging and Graphics, 2026Under Review
3D SegUX-Net: Multi-Modal MRI Segmentation Using Large KernelsMuhammad Faizan, Sara Ali, Usman Zia, and 1 more authorComputerized Medical Imaging and Graphics, 2026Under ReviewBiomedical semantic segmentation is crucial in decision-making, enabling precise localization of anomalies. While convolutional neural networks (CNNs), particularly U-shaped architectures, have been state-of-the-art (SOTA) algorithms, their limited receptive fields hinder the precise segmentation of structures with irregular shapes and sizes. Hybrid approaches integrating convolution and vision transformers (ViTs) have demonstrated improved performance due to their ability to capture long-range dependencies. However, ViTs are computationally expensive, particularly for 3D volumetric medical image segmentation, such as MRI, making them challenging to deploy on hardware with limited resources. To address these challenges, recent studies have revisited convolutional architectures, leveraging large kernel (LK) depth-wise convolution to emulate the hierarchical transformer’s behavior. Building on this direction, we propose 3D SegUX-Net, a novel U-shaped encoder-decoder architecture for volumetric biomedical image segmentation. Our model introduces the SegUX block, which combines large kernel depth-wise convolution and point-wise convolution to enhance the receptive field while maintaining computational efficiency. Empirical results demonstrate that 3D SegUX-Net consistently outperforms SOTA CNN and transformer-based architectures on multiple benchmarks, including BraTS 2019, BraTS 2020, BraTS 2023, and BTCV organ segmentation. The proposed architecture establishes new state-of-the-art performance in volumetric medical semantic segmentation, combining simplicity, efficiency, and scalability.
@article{faizan2025seguxnet, title = {{3D SegUX-Net: Multi-Modal MRI Segmentation Using Large Kernels}}, author = {Faizan, Muhammad and Ali, Sara and Zia, Usman and Sial, Muhammad Baber}, journal = {Computerized Medical Imaging and Graphics}, year = {2026}, note = {Under Review}, }
2025
-
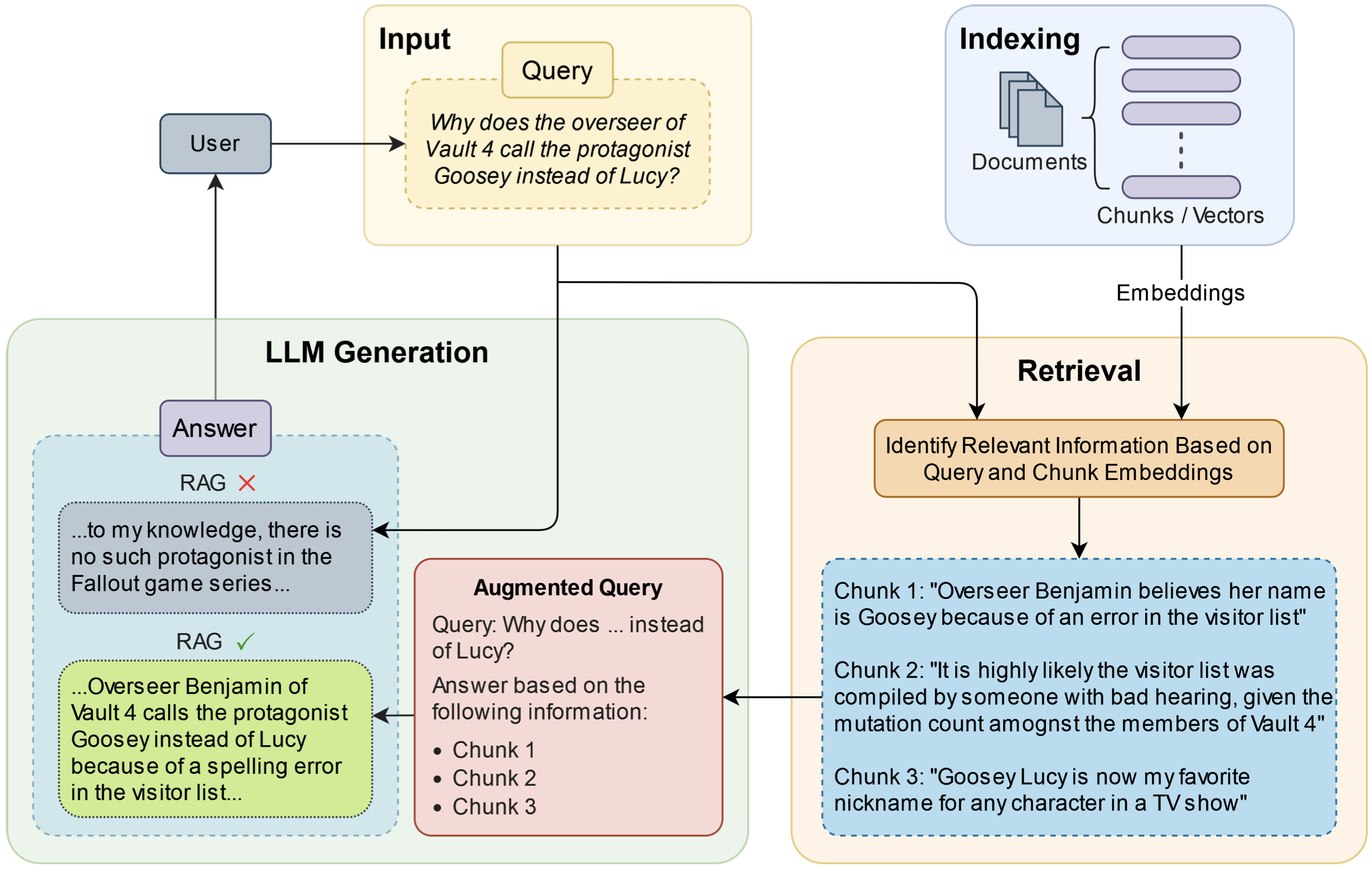 RAG Powered LLMs for QA: Evolution, Challenges, Applications, and Future DirectionsHafiz Muhammad Ali Zeeshan, Muhammad Faizan, Usman Zia, and 1 more authorIn 2025 International Conference on Communication Technologies (ComTech), 2025
RAG Powered LLMs for QA: Evolution, Challenges, Applications, and Future DirectionsHafiz Muhammad Ali Zeeshan, Muhammad Faizan, Usman Zia, and 1 more authorIn 2025 International Conference on Communication Technologies (ComTech), 2025Large language models (LLMs) are evolving to excel in challenging tasks such as text generation, mathematical reasoning, code generation, question answering, text summarization, etc. However, the responses generated by LLMs are prone to hallucinations, out-of-the-date knowledge, and non-transparent and untraceable reasoning. Retrieval augmented generation (RAG) addresses these shortcomings by incorporating external knowledge in the LLM prompt. RAG combines parametric knowledge of LLM with non-parametric knowledge from external databases by efficient retrieval techniques. This comprehensive review paper provides a detailed overview of the significance and emergence of RAG. Moreover, the building blocks of RAG are thoroughly discussed along with the evolution, challenges, and current research trends of deploying RAG-based applications. Finally, we explore the RAG performance enhancement strategies while also underlining the potential future research directions.
@inproceedings{zeeshan2025rag, title = {{RAG Powered LLMs for QA: Evolution, Challenges, Applications, and Future Directions}}, author = {Zeeshan, Hafiz Muhammad Ali and Faizan, Muhammad and Zia, Usman and Gohar, Abdullah}, booktitle = {2025 International Conference on Communication Technologies (ComTech)}, pages = {1--6}, year = {2025}, organization = {IEEE}, }
2022
-
 Vehicle Recognition using Multi-Layer Perceptron and SMOTE TechniqueAfaq Ahmad, Arshid Ali, Fadia Ali Khan, and 4 more authorsIn 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), 2022
Vehicle Recognition using Multi-Layer Perceptron and SMOTE TechniqueAfaq Ahmad, Arshid Ali, Fadia Ali Khan, and 4 more authorsIn 2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH), 2022Vehicle recognition is a significant problem to address. Primarily because of the different shapes of vehicles, it is hard for computer vision to achieve this goal. Our paper is intended to identify vehicles using a multi-layer perceptron (MLP) algorithm. The dataset used in this research is obtained from the Turing Institute, Glasgow, Scotland, present on the UCI machine learning repository website. This research consists of two stages. In the first stage, pre-processing is done in which a SMOTE filter is applied to resample a dataset. The Multi-layer Perceptron (MLP) algorithm is applied in the second stage for classification. It is pointed out that the proposed model obtained the highest classification accuracy of 86.02%. Performance of MLP is evaluated on accuracy, precision, F1-Score, and MCC.
@inproceedings{ahmad2022vehicle, title = {{Vehicle Recognition using Multi-Layer Perceptron and SMOTE Technique}}, author = {Ahmad, Afaq and Ali, Arshid and Khan, Fadia Ali and Habib, Zeeshan and Din, Zia Ud and Ali, Muhammad Zulfiqar and Faizan, Muhammad}, booktitle = {2022 2nd International Conference of Smart Systems and Emerging Technologies (SMARTTECH)}, pages = {190--193}, year = {2022}, organization = {IEEE}, }